
от 25 000 руб.











Акция «ФУНДАМЕНТ ЗА НАШ СЧЕТ»
При заказе демонтажа(сноса) дома до 25 апреля вывоз фундамента за наш счет!
При заказе демонтажа(сноса) дома до 25 апреля вывоз фундамента за наш счет!

от 25 000 руб.

от 25 000 руб.

от 25 000 руб.

| Наименование услуг | Цена за м3, руб. |
|---|---|
| Демонтаж кирпичного дома с фундаментом | от 260 |
| Снос деревянного дома на дачном участке | от 200 |
| Разбор бани с сохранением материалов | от 220 |
| Разбор сарая на участке | от 150 |
| Демонтаж дома после пожара | от 200 |
| Разборка части дома | от 180 |
| Снос частного дома с вывозом мусора | от 180 |
| Демонтаж фундамента с вывозом мусора | от 180 |
| Снос дачного дома | от 200 |
| Снести старый дом (загородный) | от 200 |






Наша компания «МеталлДемонтаж» c 2010 года осуществляет разбор и демонтаж домов, бань, сараев и других построек различной сложности по разумным ценам. За это время мы набрали лучших мастеров, необходимую специальную технику, чтобы проводить работы быстро и качественно. Опытный персонал возьмётся за снос строения вручную, если это необходимо.
Строительство в Москве и Московской области ведется интенсивно. Застроенные старыми ветхими домами площадки нужно расчистить, сотни заброшенных и недостроенных зданий в жилой застройке — разломать или разобрать, чтобы освободить место под возведение новых строений. Услуги по разборке строений специфичны — работы необходимо осуществлять, заранее распланировав проект сноса. Поэтому профессиональный и ответственный подход важен, а наша компания успешно справляется с любым заказом, не завышая стоимость.













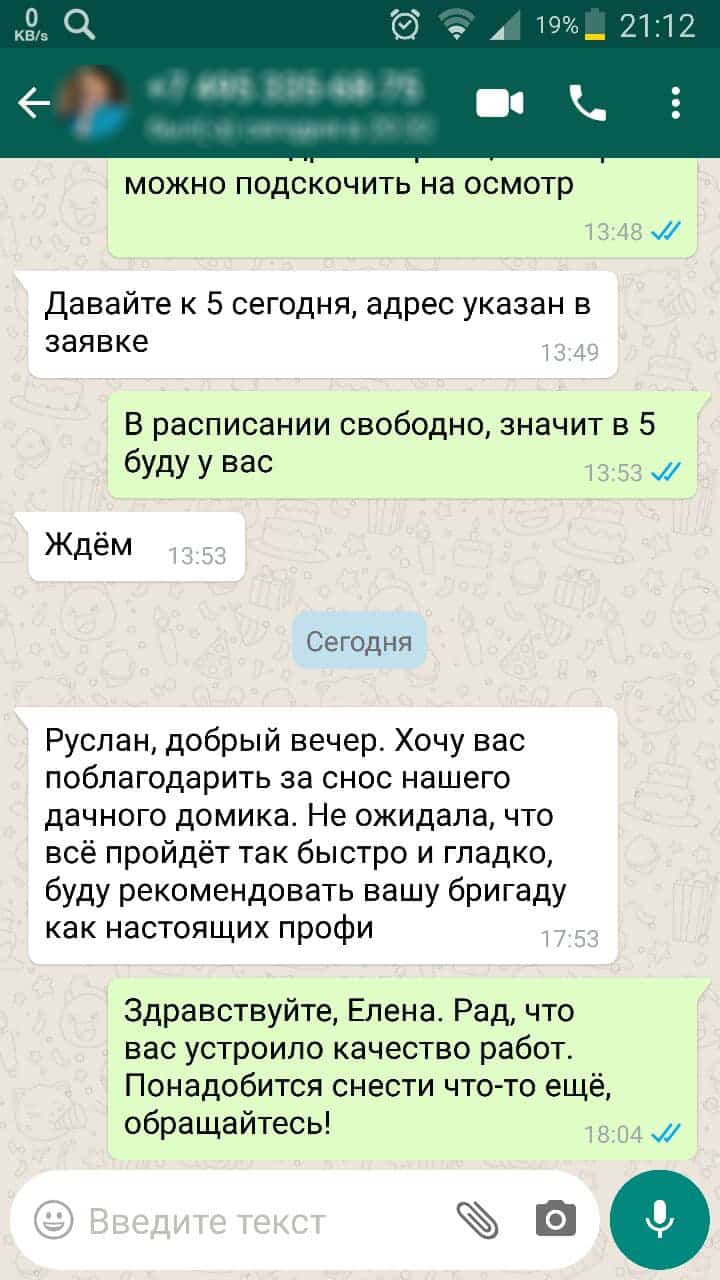

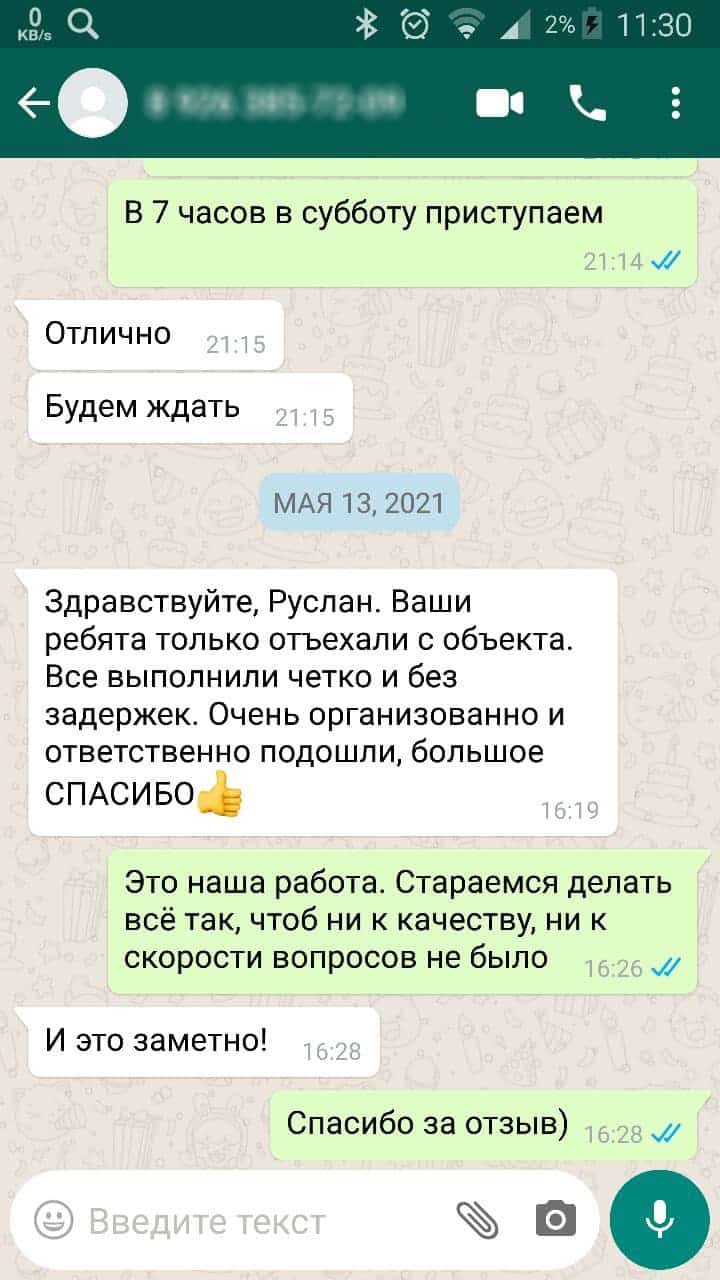
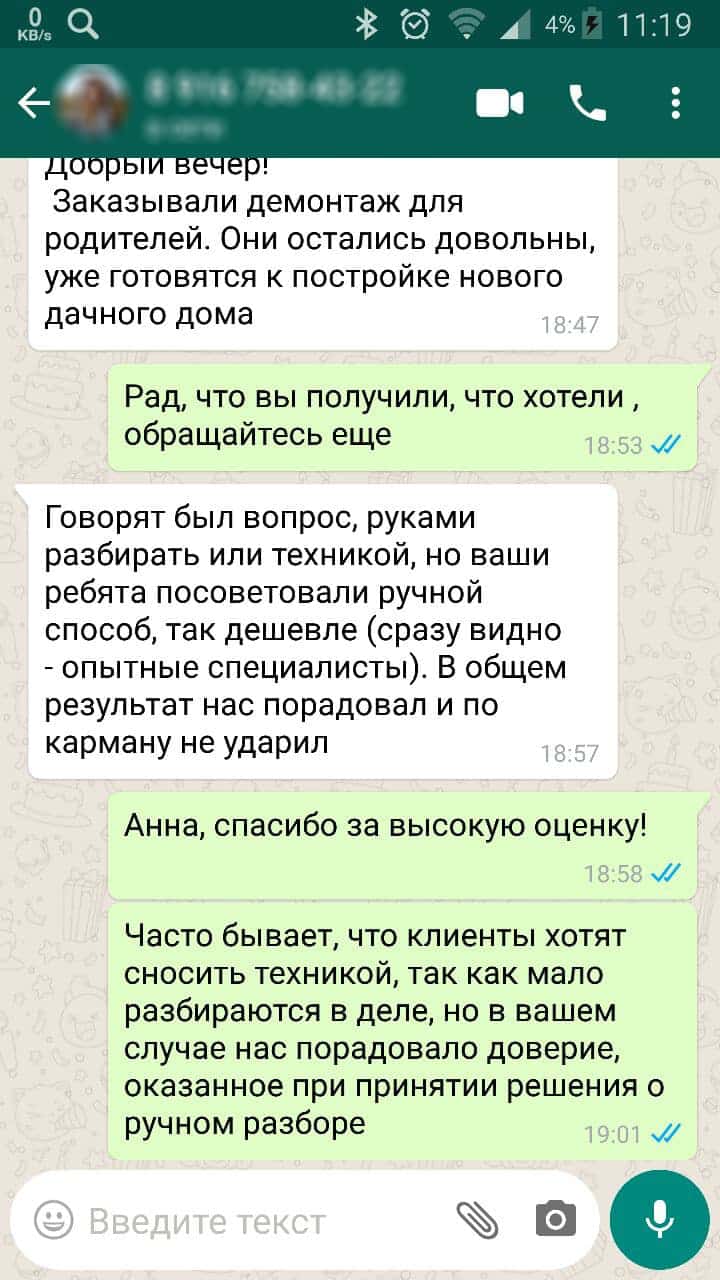

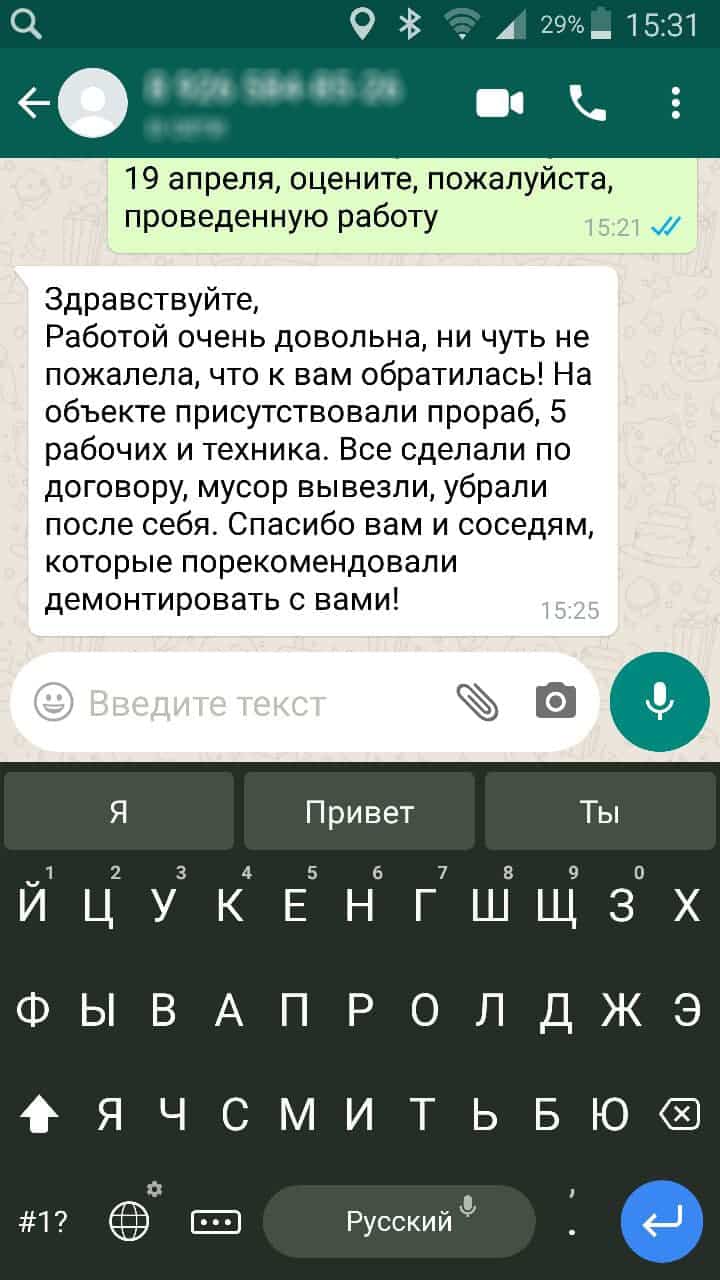
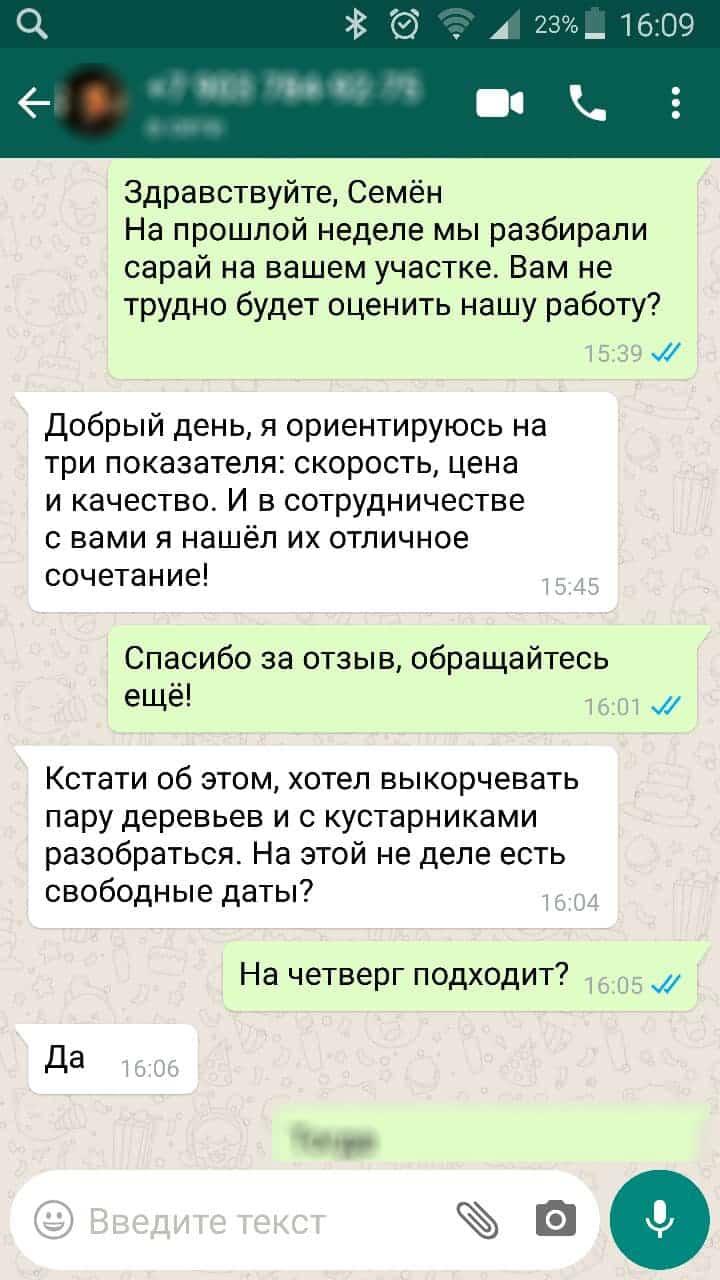
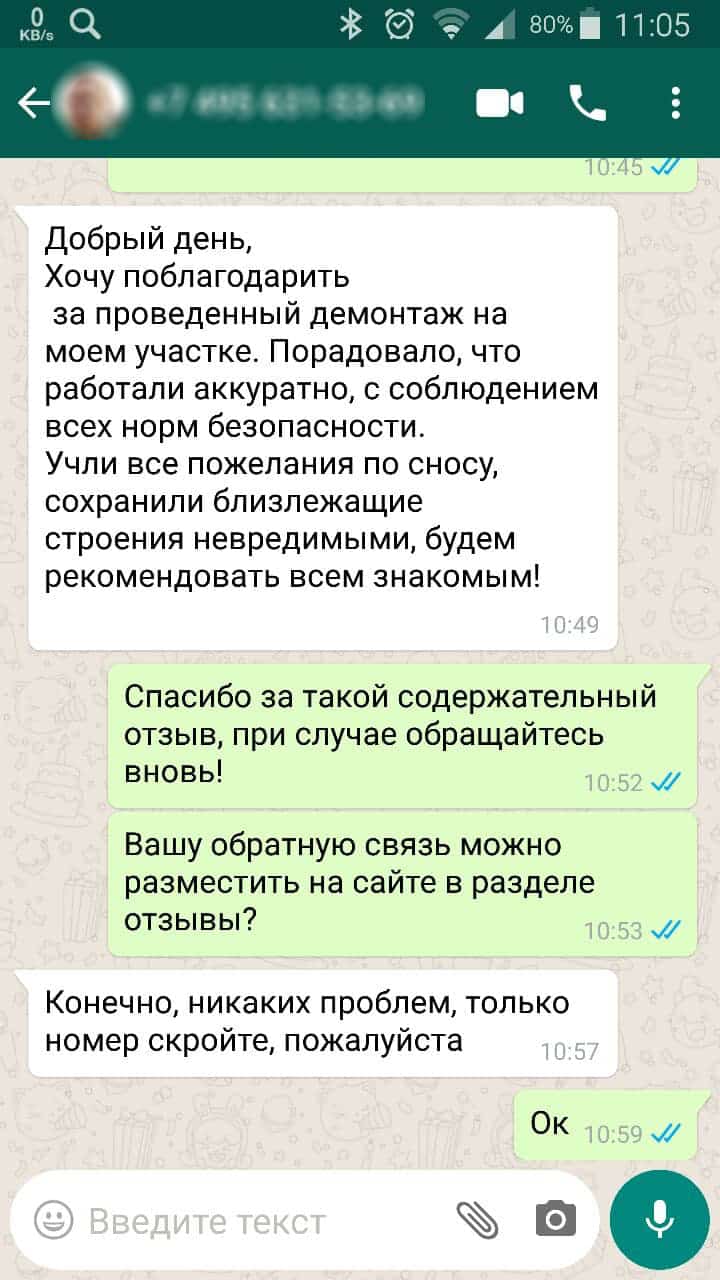




Не нашли то что искали? Не проблема, оставьте заявку и мы ответим на любые ваши вопросы.
Нашли дешевле или остались вопросы? Свяжитесь с нашим специалистом прямо сейчас и он ответит на ваши вопросы, предложит лучшую цену.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}